Berechnungen zur Funktionalen Sicherheit
Größen, Formeln und Methoden
4 Wiederherstellung und Verfügbarkeit
Bei Komponenten und Systemen, die im Fall eines Ausfalls repariert oder ersetzt werden, sind weitere Betrachtungen und Größen erforderlich.
4.1 Reparierbarkeit
Wenn davon ausgegangen werden muss, dass es während der spezifizierten Einsatzdauer des Gesamtsystems zu mehreren Ausfällen der Funktion kommen kann, ist ein System (bzw. eine Funktion) reparierbar. Dabei spielt es keine Rolle, ob das System im wörtlichen Sinne repariert wird, oder einzelne Komponenten oder sogar das ganze System durch ein gleiches oder anderes ersetzt wird. Reparierbarkeit ist also keine Definitionssache (wie die Festlegung einer kleinsten tauschbaren Einheit oder des Totalschadens), sondern ergibt sich durch die Zuverlässigkeiten der Komponenten und die geplante Einsatzdauer zwangsläufig. Die viel einfachere Modellierung einer Funktion als nicht-reparierbar darf nur dann gewählt werden, wenn die Unzuverlässigkeit sämtlicher Komponenten über die angedachte, spezifizierte Einsatzdauer klein ist (etwa kleiner 0,1). Dies ist bei langlebigen Systemen wie Flugzeugen, Eisenbahnen, Maschinen oder Industrieanlagen praktisch nie erfüllt, bei kurzlebigen wie PKW nur bei manchen Funktionen.
4.2 Diagnose, Test, Wiederherstellung
Als Diagnose bezeichnet man gemäß [IEC 61508] und anderen Normen die Maßnahmen, die einen Fehler innerhalb der Prozessfehlertoleranzzeit (PFTZ, auch als Prozess-Sicherheitszeit bezeichnet) entdecken. Das ist die Zeit, die ein physikalischer Prozess (z. B. ein Motor oder ein Ventil in einer Maschine) falsch angesteuert werden darf, ohne dass hierdurch ein unkontrollierbarer oder gefährlicher Systemzustand resultiert.
Als Tests werden die Maßnahmen bezeichnet, die Fehler erst nach einer mehr oder weniger genau definierten Fehleroffenbarungszeit offenbaren, beispielsweise im Rahmen eines Neustarts (Power-on-Self-Test), einer regelmäßig
durchzuführenden Testroutine (Prüflauf) oder bei einer Wartungsmaßnahme (Werkstattinspektion). Die mittlere Zeit, in der ein vorhandener Fehler detektiert wird, wird meist mit MTTD (engl. Mean Time To Detect)
abgekürzt. Wird ein Test in regelmäßigen Abständen
Im Fall eines erkannten Defekts wird entweder die defekte Komponente repariert oder ersetzt, oder ein ganzes Modul ersetzt oder gar das ganze System (Maschine, Fahrzeug,...) außer Betrieb genommen und durch ein neues ersetzt. In jedem Fall wird die Funktion wieder hergestellt, denn diese wird ja in der Regel weiterhin benötigt. Mit welcher Maßnahme die Funktion konkret wieder hergestellt wird, spielt für die weiteren Betrachtungen keine Rolle.
4.3 Verfügbarkeit und Nichtverfügbarkeit
Verfügbarkeit
Nichtverfügbarkeit
Die Verfügbarkeit ist die entscheidende Größe bei Systemen/Funktionen, die nur gelegentlich benötigt werden, insbesondere also Funktionen, die nur in Ausnahme- oder Notfällen benötigt werden (z. B. Alarme oder Löscheinrichtungen). Sie ist auch eine wesentliche Größe bei Systemen/Funktionen, die Redundanzen aufweisen, sogenannte mehrkanalige Systeme, hierzu später mehr.
Für eine Komponente oder ein System, welches nie getestet und somit auch nie repariert oder ersetzt wird, gilt:
Die Verfügbarkeit kann durch kontinuierliche Diagnose oder regelmäßige Tests und falls nötig Wiederherstellung maßgeblich erhöht werden. Dies ist der Grund, warum praktisch alle Notfallsysteme regelmäßig getestet werden.
Wenn eine Komponente getestet und im Fall eines Defekts repariert oder ausgetauscht wird, gilt
Da aber nicht bekannt ist, wann der erste Defekt auftritt und somit die erste Reparatur oder der erste Austausch erforderlich ist, ist diese Formel praktisch bedeutungslos. Aus demselben Grund ist auch eine veränderliche Ausfallrate
praktisch bedeutungslos, denn man kann ja nie sagen, wie lange zum Zeitpunkt
Die Nichtverfügbarkeit ist für Komponenten und Systeme, welche regelmäßig (und vollständig) getestet werden, daher eine periodische Aneinanderreihung von Anfangsstücken der Exponentialverteilung:
Ist die Zeit
Für eine mittlere Ausfallrate
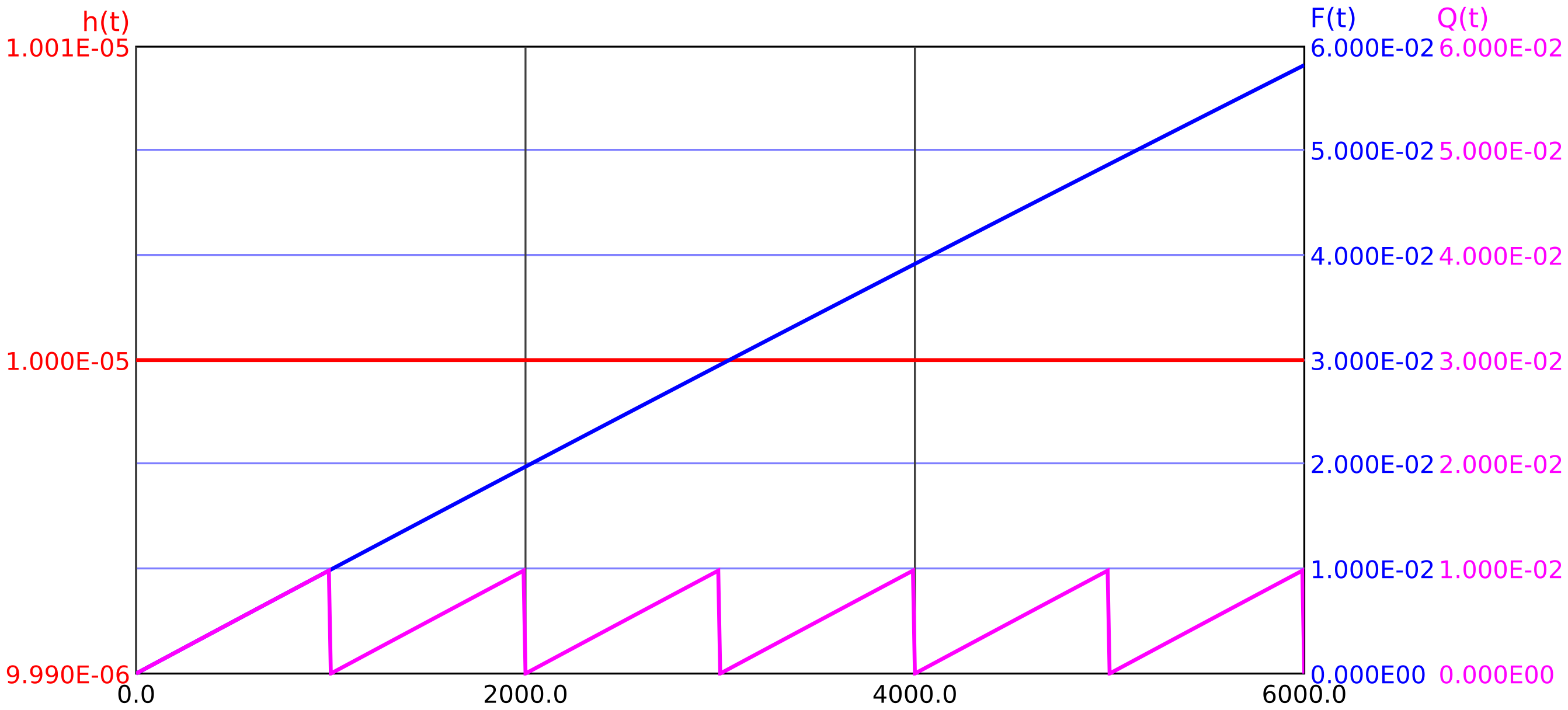
Die Nichtverfügbarkeit sinkt bei jedem Test auf null, um dann erneut anzusteigen. Dabei wird vorausgesetzt, dass der regelmäßige Test vollständig ist, also alle relevanten Fehler der Komponente offenbart. Ist dies nicht der Fall, muss dieser verbleibende Anteil als weitere Nichtverfügbarkeit mit einer entsprechend kleineren Ausfallrate, aber längeren Testzeit (dann meist die System-Lebenszeit) hinzugefügt werden. Überschlagsmäßig kann man diese zweite Nichtverfügbarkeit einfach addieren, in speziellen Software-Werkzeugen (FTA- oder Markov-Tools) ist auch eine exakte Behandlung möglich.
-
Beispiel 4.1 Ein Rauchmelder habe eine mittlere Ausfallrate von
Es muss die mittlere Nichtverfügbarkeit über das Testintervall
Wenn die Nichtverfügbarkeit klein ist (etwa
Im vorherigen Beispiel ergäbe sich
Die Nichtverfügbarkeit ist zwar wie die Unzuverlässigkeit eine Wahrscheinlichkeit, kann also nur Werte von 0 bis 1 annehmen, sie ist jedoch im Gegensatz zur Unzuverlässigkeit nur im Sonderfall eines nicht-testbaren
Systems monoton steigend. Nach jedem Test hingegen fällt die Nichtverfügbarkeit
4.4 Zeit zur Reparatur, MRT
Falls durch den Defekt nur eine Teilfunktion betroffen ist, der Weiterbetrieb des umgebenden größeren Systems aber (ggf. mit Einschränkungen) möglich ist, muss auch die für die Reparatur und/oder Ersatzbeschaffung benötigte Zeit (MRT, Mean Repair Time) in der Verfügbarkeit berücksichtigt werden. Zusammen mit der Zeit zur Entdeckung (MTTD) ergibt sich die mittlere Wiederherstellungszeit (Mean Time To Restore, MTTR):
Zur exakten Berechnung der mittleren Nichtverfügbarkeit kann man von deren Definition ausgehen:
Dabei bezeichnet
und
Durch Einsetzen in Formel (43) ergibt sich für die mittlere Nichtverfügbarkeit
Für vernachlässigbare Detektionszeit
wie man durch einmalige Anwendung der Regel von de l’Hospital auf Formel (44) erhält.
Für vernachlässigbare Reparaturzeit
Wenn sowohl Testintervall
Schwieriger ist die Herleitung einer (exakten) Formel für die Nichtverfügbarkeit zu einem bestimmten Zeitpunkt, wenn die Reparaturzeit nicht vernachlässigbar klein ist. Eine sehr gute Näherung ist durch
gegeben (ohne Herleitung). Für Reparaturzeit
Für vernächlässigbare Detektionszeit
also Formel (45).
4.5 Kontinuierliche Diagnose
Im Fall von kontinuierlicher vollständiger Diagnose (d. h. jeder Fehler wird sofort entdeckt) hat die Nichtverfügbarkeit gar nichts mit der (Un-)zuverlässigkeit zu tun, es gilt also immer
Wird die Komponente nie getestet und ggf. repariert oder ersetzt, so ist
-
Beispiel 4.2 Eine Komponente mit der konstanten Ausfallrate
4.6 Betriebliche und sicherheitsbezogene Verfügbarkeit
Häufig hört man als Sicherheitsingenieur den Satz: „Der Ausfall ist unkritisch, der geht nur in die Verfügbarkeit.“ Dieser Satz basiert auf dem Unverständnis von Zuverlässigkeit und Verfügbarkeit. Beides können sicherheitsbezogene Größen sein, müssen aber nicht.
-
Beispiel 4.3 Die Verfügbarkeit eines Rauchmelders gibt an, mit welcher Wahrscheinlichkeit er eine Rauchentwicklung melden wird. Dies ist offensichtlich eine sicherheitsrelevante Größe, in vielen Anwendungen gibt es daher vorgeschriebene Mindestwerte (bzw. Maximalwerte für die Nichtverfügbarkeit). Je häufiger man ihn testet, umso größer wird die Verfügbarkeit. Je größer die Ausfallrate, um so häufiger muss man testen (und reparieren), um die geforderte Verfügbarkeit zu erreichen. Die Zuverlässigkeit (oder Ausfallrate) alleine erlaubt hier keine Aussage über die Sicherheit, da es für die Gebäudesicherheit unrelevant ist, wie oft der Rauchmelder kaputt geht – wenn der Fehler nur schnell detektiert und behoben wird. Vielmehr ist die Zuverlässigkeit hier eine betrieblich relevante Größe: Je schlechter die Zuverlässigkeit (also je größer die Ausfallrate) des Rauchmelders, desto häufiger muss man ihn testen und ersetzen, um die aus Sicherheitsgründen vorgegebene Verfügbarkeit zu erreichen.
4.7 Ausfallrate bei Tests
Aufgrund der Tests und ggf. Reparatur verliert die Dichtefunktion
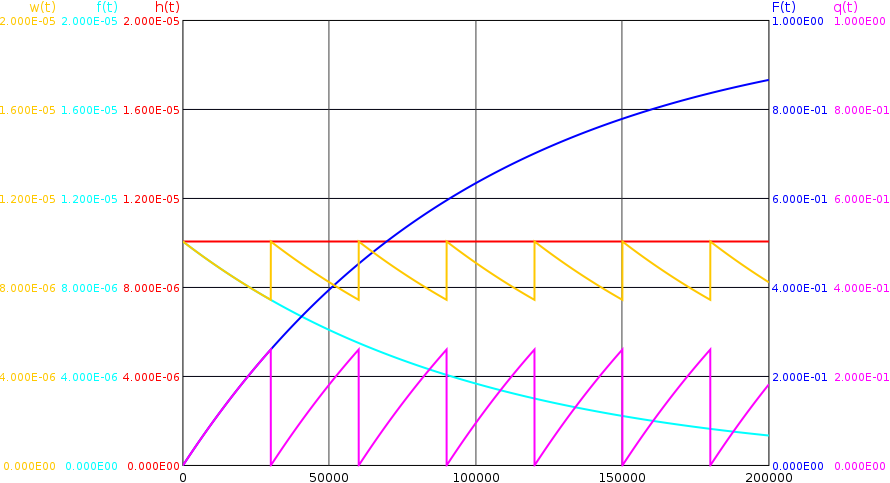
Im Gegensatz zur Dichte
Die Ausfallrate, also die Häufigkeit des Übergangs in den Ausfallzustand unter der Bedingung, dass das System zum Zeitpunkt
wobei